Architecture
High-level architectural overview of jeeves-runner for contributors and advanced users.
Design Principles
- Graph-aware, domain-agnostic — The runner knows about sources, sinks, datastores, queues, and processes. It does not know about "emails" or "meetings."
- SQLite is the source of truth — Jobs, runs, state, and queues all live in a single SQLite database.
- Two execution modes — Script jobs spawn child processes; session jobs dispatch to the OpenClaw Gateway.
- File + table duality — Datastores that produce artifacts for indexing or serving use the filesystem; operational state uses SQLite.
- Schedule-driven — All job execution is driven by cron expressions with prime-offset scheduling to spread load.
System Architecture
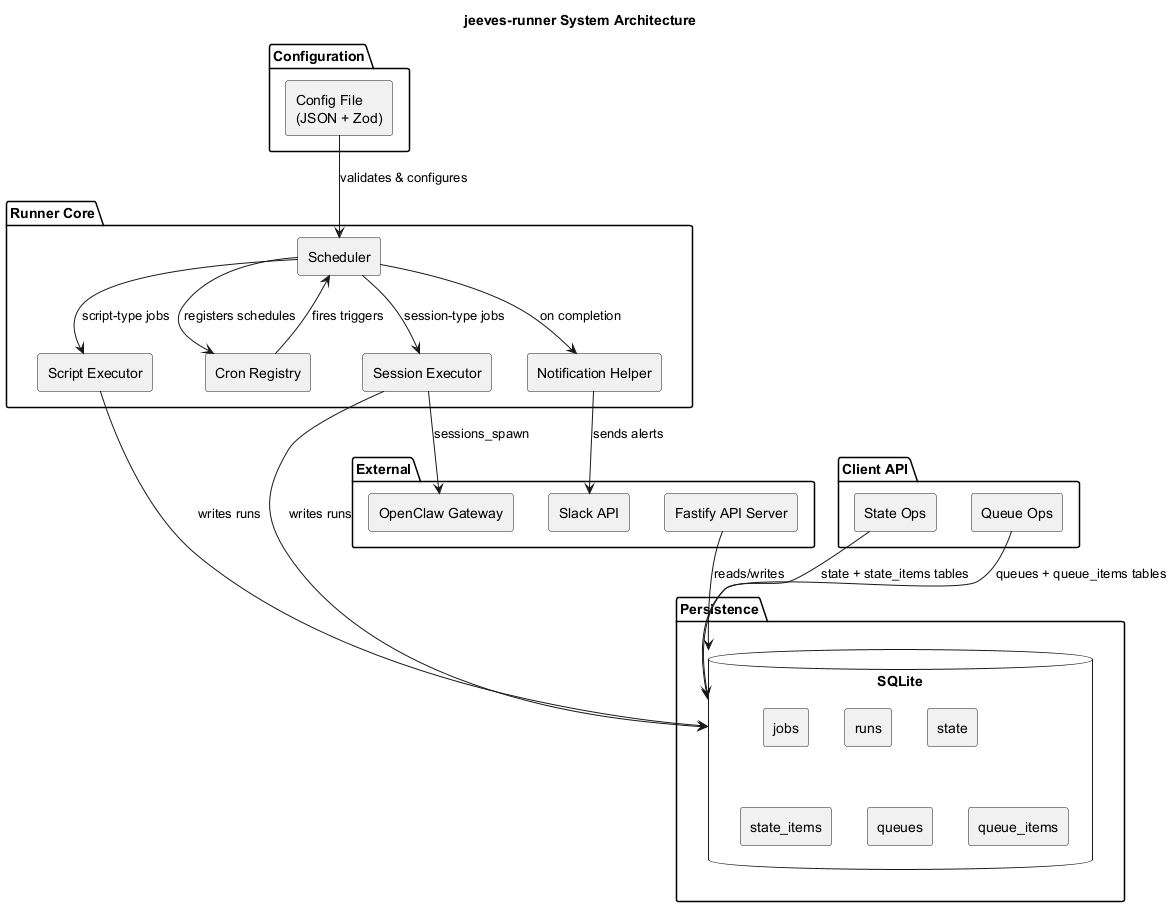
The runner consists of several layered components:
- Configuration Layer — Zod-validated config with sensible defaults
- Scheduler Layer — Cron registry, job reconciliation, and execution dispatching
- Execution Layer — Script executor (child processes) and session executor (Gateway dispatch)
- Persistence Layer — SQLite database with jobs, runs, state, state_items, queues, and queue_items tables
- API Layer — Fastify HTTP server for job management and monitoring
- Client API — Programmatic access to state and queue operations
- Notification Layer — Slack integration for job completion alerts
Job Lifecycle
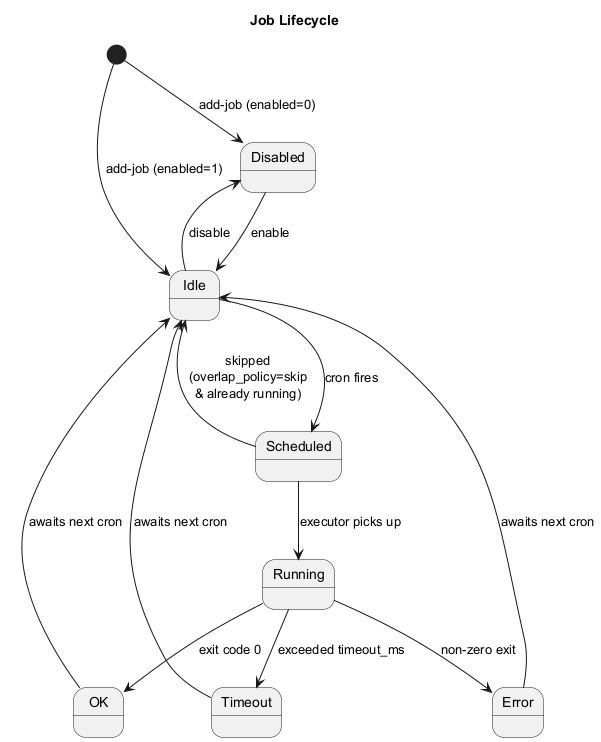
Jobs transition through these states:
- Disabled — Job exists but will not be scheduled
- Idle — Job is enabled and waiting for the next cron trigger
- Scheduled — Cron has fired; job is queued for execution
- Running — Executor is actively running the job
- OK — Job completed successfully (exit code 0)
- Error — Job failed (non-zero exit code or exception)
- Timeout — Job exceeded its configured timeout
Overlap Policy
Each job has an overlap_policy:
- skip (default) — If the job is already running when the next cron fires, the new run is skipped
- allow — Multiple instances can run concurrently
Data Flow
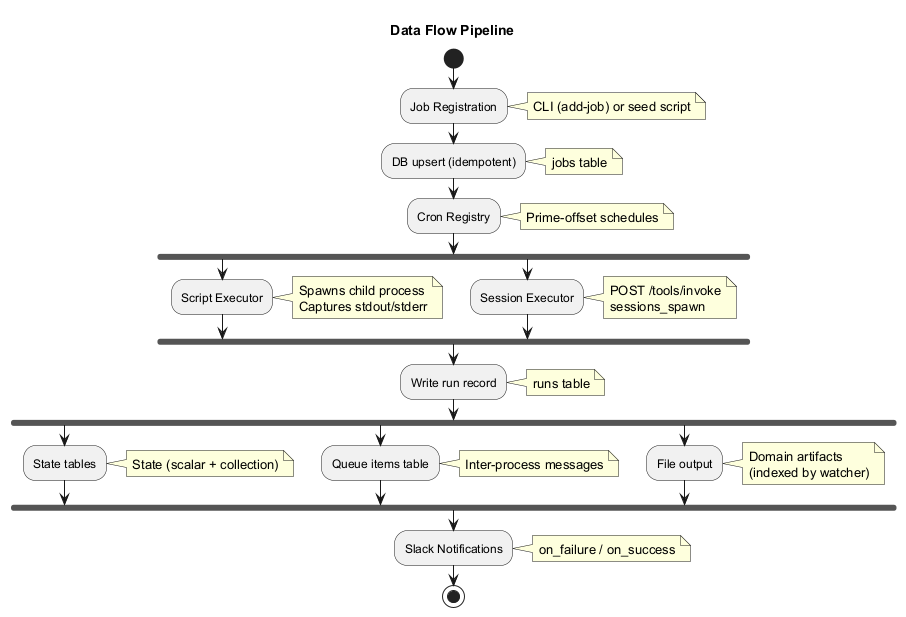
Job Registration
Jobs are registered via the jeeves-runner add-job CLI command or programmatically via a seed script (e.g., scripts/seed-jobs.ts). Registration upserts into the SQLite jobs table — the database is the live source of truth.
Execution Pipeline
- Cron Registry fires at the scheduled time
- Scheduler checks overlap policy and concurrency limits
- Executor dispatches the job:
- Script jobs: spawns a child process with the configured script path
- Session jobs: calls the OpenClaw Gateway
/tools/invokeendpoint withsessions_spawn
- Run record is written to the
runstable with status, duration, exit code, stdout/stderr - Notifications are sent via Slack if configured (per-job or default channels)
State and Queue Tables
Scripts can persist state and exchange data through the runner's client API:
- State tables — Scalar key-value store (
state) with optional TTL, plus collection state (state_items) for tracking sets of items. Scripts usegetState/setState/deleteStatefor scalar state andhasItem/getItem/setItem/deleteItem/countItems/pruneItems/listItemKeysfor collection state. - Queue tables — Queue metadata (
queues) with dedup config and retention, plus ordered queue items (queue_items) with claim semantics. Producers enqueue items; consumers claim and complete them. Used for inter-process data passing.
SQLite Schema
jobs Table
Stores job configuration. Registered via CLI or seed script, mutable via API.
| Column | Type | Description |
|---|---|---|
id |
TEXT PK | Unique job identifier |
name |
TEXT | Human-readable name |
schedule |
TEXT | Cron expression |
script |
TEXT | Absolute path to executable script |
type |
TEXT | script or session |
enabled |
INTEGER | 1 = enabled, 0 = disabled |
timeout_ms |
INTEGER | Timeout in milliseconds (null = no timeout) |
overlap_policy |
TEXT | skip or allow |
on_failure |
TEXT | Slack channel for failure alerts |
on_success |
TEXT | Slack channel for success alerts |
runs Table
Stores execution history. Automatically pruned based on runRetentionDays.
| Column | Type | Description |
|---|---|---|
id |
INTEGER PK | Auto-increment run ID |
job_id |
TEXT FK | References jobs.id |
started_at |
TEXT | ISO 8601 timestamp |
finished_at |
TEXT | ISO 8601 timestamp |
status |
TEXT | ok, error, or timeout |
exit_code |
INTEGER | Process exit code |
stdout |
TEXT | Captured standard output |
stderr |
TEXT | Captured standard error |
duration_ms |
INTEGER | Execution duration |
state Table
Scalar key-value store for script operational state.
| Column | Type | Description |
|---|---|---|
namespace |
TEXT | Logical grouping (typically job ID) |
key |
TEXT | State key |
value |
TEXT | JSON-encoded value |
expires_at |
TEXT | Optional TTL timestamp |
state_items Table
Collection state for tracking sets of items within a namespace.
| Column | Type | Description |
|---|---|---|
namespace |
TEXT | Logical grouping (typically job ID) |
key |
TEXT | Collection key |
item_key |
TEXT | Individual item identifier |
value |
TEXT | JSON-encoded value |
expires_at |
TEXT | Optional TTL timestamp |
queues Table
Queue-level metadata including deduplication and retention configuration.
| Column | Type | Description |
|---|---|---|
id |
TEXT PK | Queue identifier |
dedup_config |
TEXT | JSON deduplication configuration |
retention |
TEXT | JSON retention policy |
queue_items Table
Ordered message queue with claim semantics.
| Column | Type | Description |
|---|---|---|
id |
INTEGER PK | Auto-increment |
queue_id |
TEXT FK | References queues.id |
payload |
TEXT | JSON-encoded payload |
status |
TEXT | pending, claimed, completed, failed |
created_at |
TEXT | Enqueue timestamp |
claimed_at |
TEXT | Claim timestamp |
completed_at |
TEXT | Completion timestamp |
Gateway Integration
Session-type jobs delegate execution to the OpenClaw Gateway:
- Runner reads the gateway
urlandtokenPathfrom config - On trigger, the session executor calls
POST /tools/invokewithsessions_spawn - The gateway creates an isolated agent session that executes the task
- Results flow back through the gateway response
Requirement: The gateway must have sessions_spawn in gateway.tools.allow (it is on the default HTTP deny list).